Featured Articles

vLLM: Smart Handling of Complex & Multiple User Behaviors in LLMs
Explore how vLLM efficiently manages parallel sampling, beam search, shared prompt caching, and batching mixed requests. Learn how it improves LLM inference with smart memory scheduling, KV cache sharing, and dynamic task handling across GPUs.

LLM PagedAttention: Efficient KV Cache, Batching and Scalable Inference
Know PagedAttention solves memory inefficiency, solves KV cache problem in LLM and multiple request batching challenges in large language model, LLM inference and serving. GPU memory utilization, reduce latency, and high throughput AI infrastructure.

LLM Cost Reduction - KV Caching + Batching = 67% Savings
Discover how KV caching and intelligent batching strategies drastically reduce LLM inference costs by over 60%. Learn how to increase throughput, reduce latency, and improve GPU utilization for large language models.
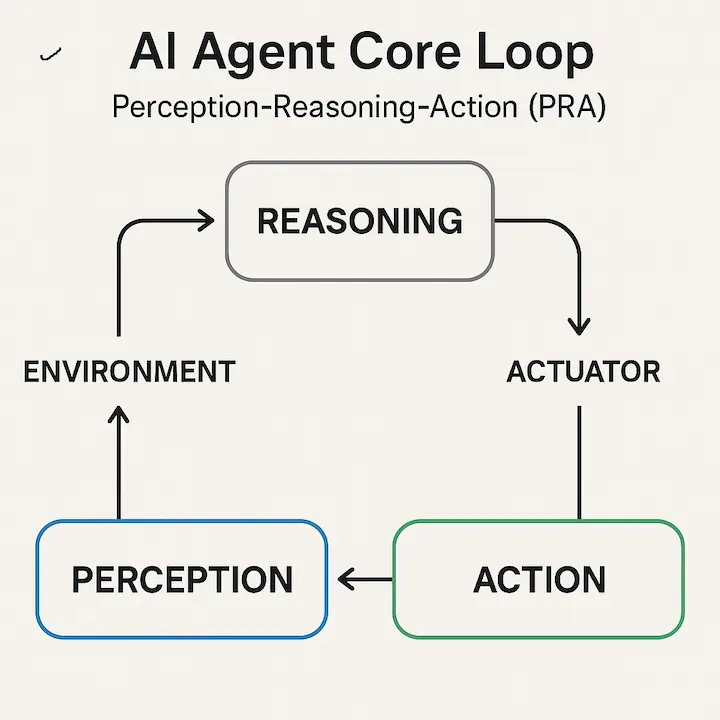
AI Agents Explained: Perception, Reasoning, Action & Architecture
Understand what AI agents are, how they perceive, reason, act, and evolve. Learn about their architecture, memory systems, learning mechanisms, and key frameworks.
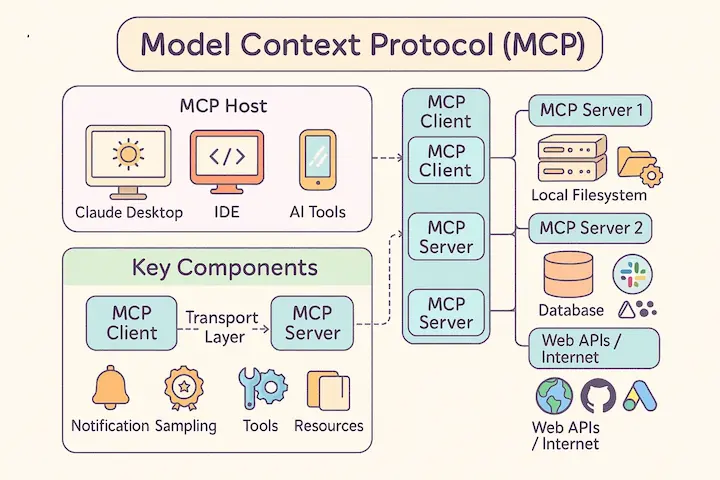
Model Context Protocol (MCP) Explained
Understand what Model Context Protocol (MCP) is, how it works, and why it’s becoming the new standard for integrating AI with real-world tools and systems.

LLMs Are Revolutionizing Predictive Retail
Discover how Large Language Models (LLMs) are transforming predictive retail—from personalized shopping to dynamic pricing and multimodal AI.
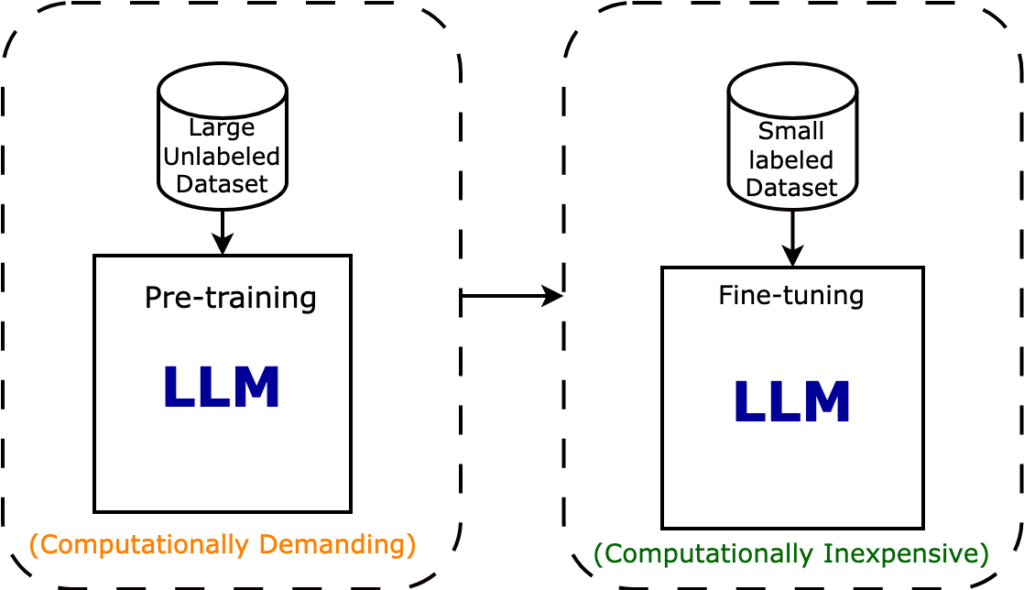
Rise of Agentic AI Workflows
Explore how autonomous multi-agent systems collaborate to complete complex AI tasks effectively.